
Beamr will be exhibiting at this year’s Autonomous Vehicle Tech Expo (June 23-25, 2026, Stuttgart, Germany), and AAVI recently asked the company about what ML-safe compression requires across the AV pipeline, in an exclusive feature first published in the April 2026 issue, which you can read below:
Across the autonomous vehicle industry, compression is no longer optional. Fleets produce vast volumes of real-world footage, while synthetic data from world foundation models often exceeds that volume. Datasets are growing faster than ML pipelines can absorb, creating compounding pressure on storage, data transfer, pipeline throughput and development timelines.
Many teams building ADAS and AV systems are already compressing video data or evaluating how to. But compression introduces a critical question the industry has not rigorously answered: How do you confirm that compressed video preserves ML model integrity across every scenario and pipeline stage?
The challenge is that the industry lacks a shared validation framework to answer this question. No shared methodology exists to define exactly what ‘ML-safe compression at scale’ requires. And the stakes are high. AV pipelines operate a full stack: perception models for detection and depth estimation, embedding models for dataset curation and captioning models for scene annotation. Without a validation framework covering the full model pipeline, compression decisions remain fundamentally unverified.
What an ML-safe framework must cover
Until now, teams had to define their own metrics and evaluation criteria for perceptual similarity, depth estimation and functional testing. Without industry benchmarks, each team had to run their own tests and make compression decisions without any reference for what verification is actually required.
In this uncharted territory, programs that applied standard compression without demonstrated evidence discovered model accuracy impacts downstream, forcing reversions to less compressed formats, delayed timelines and lost development velocity.
The starting point is understanding what ML models actually depend on – object boundaries, structural edges and scene geometry – rather than the smooth gradients and color transitions that human viewers tend to notice. A validation framework for AV pipelines must therefore evaluate compression from the perspective of model behavior, not visual appearance.
Such a framework must cover depth estimation, semantic embeddings and scene captioning for VLM pipelines. It should run over data types, from real-world fleet footage to synthetic training data, and it should define comparison baselines and verify how optimized compression compared against conventionally encoded video, the method used by many AV teams.
Fits into existing pipelines
For most AV teams, the practical question isn’t whether compression works – at petabyte scale,
it has become essential. The question is whether a new compression solution will disrupt the current ML infrastructure.
Beamr’s Content-Adaptive Bitrate compression (CABR) integrates directly into existing pipelines without requiring additional hardware or proprietary dependencies downstream. If GPU hardware is already in the stack, CABR runs on it – handling petabyte-scale throughput without new compute infrastructure.
It works on already-encoded archives and newly ingested footage, meaning existing datasets can be optimized without starting from scratch. Output is in standard codecs – AVC, HEVC, AV1 – ensuring compatibility with existing decoders, analytics tools and media workflows.
Deployment is flexible: as a managed solution in public or private cloud, via FFmpeg plug-in or SDK integration (Python, C++, Node.js). Video data is processed locally if required.
Evidence from real-world data
To evaluate this framework, Beamr conducted a structured series of benchmarks spanning the ML model lifecycle. The benchmarks verified that Beamr’s patented Content-Adaptive Bitrate (CABR) technology addresses this challenge directly. Rather than applying uniform compression parameters, CABR analyzes each frame individually – compressing as aggressively as the content allows, while preserving the structural details ML models depend on.
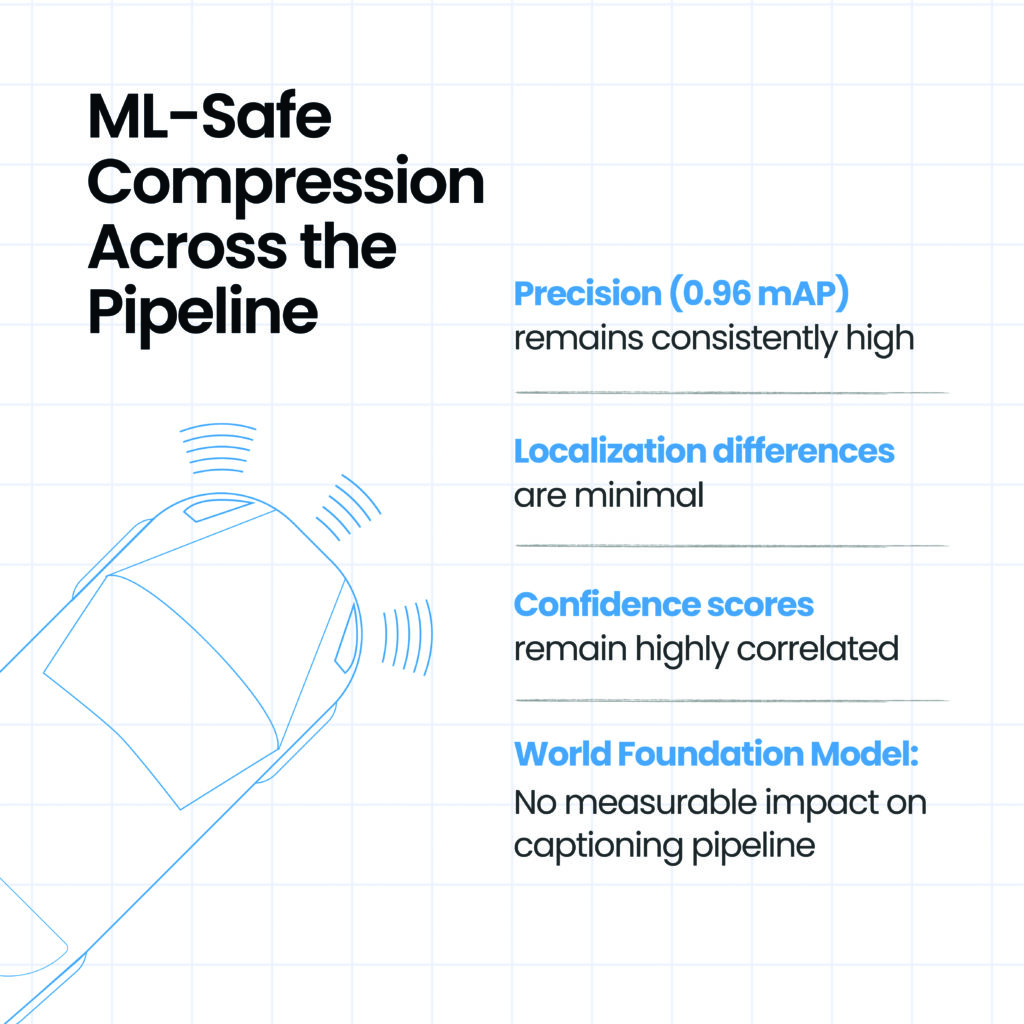
Testing against well-known AV datasets – including challenging scenarios with complex camera configurations and diverse environmental conditions – confirmed file size reduction of up to 50% while preserving ML model accuracy across evaluation metrics.
In testing for object detection, mean average precision (mAP) changed by less than 2%, remaining well within the model’s expected variance. Model output was preserved with high consistency across three dimensions: detections and classifications aligned closely, localization differences were minimal, and confidence scores remained highly correlated.
Testing with the world foundation model pipeline demonstrated that 41-57% smaller videos, optimized by Beamr’s technology, introduced no measurable impact on the captioning pipeline beyond the model’s inherent stochastic variability.

Validation across the pipeline
The differentiator is compression with proof. Programs operating without a demonstrated framework are making infrastructure bets they cannot verify, accumulating data assets the integrity of which they cannot confirm. For teams managing tens or hundreds of petabytes, the infrastructure case is straightforward once the integrity question is settled. Storage, egress, I/O time and pipeline throughput all improve with compression gains.
A framework that confirms compression safety across the current pipeline – object detection, VLM semantic fidelity, world foundation model outputs – is also building the evidence base for what comes next. Programs that establish it now are not just solving today’s infrastructure problem, they are determining what will be possible with their data two and three years from now.
This article was first published in the April 2026 issue of ADAS & Autonomous Vehicle International magazine. Read the article in its original format, here. Subscribe to receive future issues, here.