
ADAS & Autonomous Vehicle International sits down with Plus staff research engineers Anurag Paul and Inderjot Saggu to discuss the company’s three-layer architecture that is powering autonomous trucking’s move from research into real-world deployment, ahead of their presentation at ADAS & Autonomous Vehicle Technology Summit North America 2025, which will take place at the San Jose McEnery Convention Center on August 27 & 28.
What is your presentation about?
The presentation is titled Reimagining autonomous trucking with VLMs and end-to-end models. In recent years, autonomous trucking has moved from R&D to real-world commercial deployment. This talk will introduce Plus’s three-layer architecture powering this shift – vision language models (VLMs), end-to-end models and safety guardrails. We’ll share how: VLMs help with meta decisions and handle long tail problems; end-to-end models enable scalable deployment across diverse regions and vehicle platforms; and safety guardrails provide sanity checks to prevent radical maneuvers. Together, these form a robust, scalable and interpretable foundation for safe and generalizable autonomous driving.
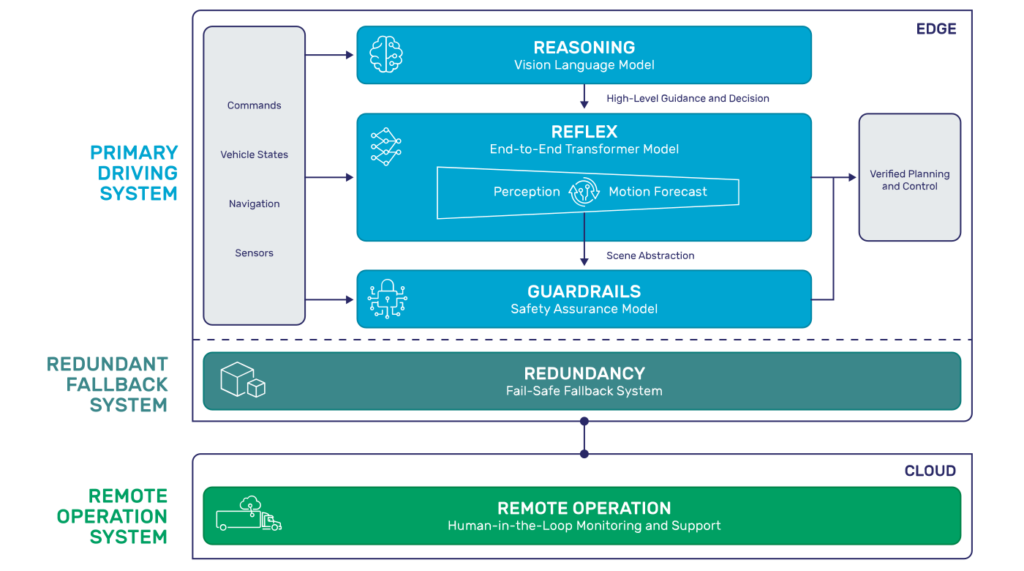
Why did Plus choose a three-layer architecture to power the shift for autonomous trucking?
Our three-layer architecture – reasoning, reflex and guardrails – is part of our AV2.0 strategy. This architecture reflects how skilled human drivers operate. They make sense of complex environments (reasoning), respond fluidly in real time (reflex) and follow rules of the road (guardrails). We modeled our system the same way.
- Reasoning, powered by vision language models, handles holistic scene understanding, resolves complex and rare scenarios and enables high-level decision-making.
- Reflex, driven by end-to-end transformer models, performs semantic scene understanding and executes the reasoning layer’s decisions with speed and precision.
- Guardrails, a rule-based safety layer, ensures every maneuver adheres to codified human driving standards.
This structure allows us to deploy on production vehicles from the factory floor, adapt quickly to new regions, and maintain high levels of safety and explainability.
How do vision language models, end-to-end models and safety guardrails form a robust, scalable and interpretable foundation for safe and generalizable autonomous driving?
VLMs provide strategic, high-level reasoning, understanding semantics, context and intent in complex scenes. This enables our autonomous driving system to handle rare or ambiguous scenarios in a human-like way. End-to-end models execute the driving behavior with high efficiency and precision. These transformer-based networks fuse perception and motion planning to generate fluid, real-time maneuvers from raw sensor input. Safety guardrails serve as a validation layer. They enforce human-defined constraints and regulatory standards to ensure that no decision, no matter how sophisticated, violates safety boundaries.
These layers together make our system generalizable across regions and interpretable. Major global OEMs like Traton (Scania, MAN, International), Hyundai Motor Company, and IVECO have selected us to power their autonomous truck programs. We’re working toward the commercial launch of factory-built autonomous trucks by 2027, starting in the USA with active testing already underway in places like the Texas Triangle.
This level of deep integration and our AV2.0 strategy enable us to safely scale autonomous trucking across the USA, Europe and beyond, wherever our OEM partners operate.
How do VLMs help with meta decisions and handle long tail problems?
Our reasoning layer uses a vision language model to provide strategic, high-level decision-making. This is a key capability for handling long tail scenarios in autonomous driving.
The VLM takes in multi-modal input and interprets the full scene: objects, lanes, context, intent and interactions. It then outputs high-level guidance, which is passed to the reflex model to inform real-time maneuvers.
Because VLMs are trained on vast amounts of data, they demonstrate strong zero-shot generalization. That means they can handle new or rare scenes like construction zones, accident sites or non-standard human behaviors without needing task-specific training.
And importantly, they support meta decisions: assessing whether the current scene is within the operational design domain, whether to trigger a fallback or when to escalate to remote operations.
This kind of semantic reasoning gives our system human-like judgment in unfamiliar conditions. It’s crucial for safe and scalable deployment.
How do end-to-end models enable scalable deployment across diverse regions and vehicle platforms?
Our reflex layer uses a transformer-based end-to-end model that fuses perception and motion planning into a single, unified network. This streamlined structure is a major enabler for scalable deployment.
Traditional autonomy stacks are modular and hand-tuned. Each component, like object detection, tracking, prediction and planning, is separate and must be adapted manually for each region, road type or vehicle. That creates friction when trying to scale.
Our end-to-end model learns directly from raw sensor data to generate driving behavior, making it inherently more adaptable. When we move into new regions, say from Texas to Germany, we don’t need to redesign every component. Instead, we can fine-tune the model on local data, enabling it to learn new traffic norms, road structures or driving cues efficiently.
This architecture also makes it easier to scale across different vehicle platforms. We can deploy it seamlessly across our OEM partners’ production-grade redundant platforms, whether it’s an International in the USA, Scania in Europe or a Hyundai Xcient Fuel Cell truck.
How do safety guardrails provide sanity checks to prevent radical maneuvers?
Our safety guardrails layer is a transparent, rule-based expert system that continuously monitors the outputs of the AI driving stack.
While our reasoning and reflex layers are powered by advanced AI models, guardrails serve as a sanity check to ensure every decision adheres to human driving standards and regulatory constraints.
If the end-to-end model proposes a maneuver that exceeds speed limits, violates traffic laws or appears unsafe – for example, taking an overly aggressive lane change or responding unpredictably to a construction zone – the guardrails will block, override or modify that output before execution. These guardrails are codified using verifiable constraints, which makes them interpretable.
Why did you choose to speak on this topic at ADAS & Autonomous Vehicle Technology Summit North America 2025?
After years of research and limited pilots, the autonomous truck industry is finally turning the corner toward real-world driver-out deployment. We wanted to speak about our AV2.0 architecture, and the application of VLMs and an end-to-end approach, to share our modern, AI-native framework built for deployment.
And the timing couldn’t be more relevant. At Plus, we’re already operating on public roads in the USA, testing across Germany and Sweden, and working closely with OEM partners like Traton, Hyundai and IVECO to launch factory-built autonomous trucks by 2027. We believe sharing what we’ve learned can help accelerate safe deployment for the entire ecosystem.
Who are you hoping will benefit from the presentation?
The session really is for anyone involved in developing autonomous driving technology and bringing it to the market, whether you’re building, integrating or regulating autonomous systems. Our goal is to share how we’ve structured our AV2.0 architecture to achieve global deployment with factory-built autonomous vehicles.
Attendees can expect to walk away with a clear understanding of how our AV2.0 architecture enables safe, scalable deployment and practical insights into how strategic AI design choices translate into real-world operations across multiple geographies and OEM platforms.
Paul and Saggu will give their presentation ‘Reimagining autonomous trucking with VLMs and end-to-end models’ as part of the ‘Developments in AI, architecture and software’ session at ADAS & Autonomous Vehicle Technology Summit North America Conference on August 27, at 12:45pm in Room 2.
![]()