
Perception is the ability to turn inputs from the world into meaning, and it is a fundamental part of every autonomous driving (AD) vehicle. Each company involved in AD has its own approach in deciding which perception sensor suite to adopt, how to place the sensors and how to use the fused collected data.
Lidar, a piece of hardware which has undergone a rapid evolution over the past few years, has recently become the protagonist in the AD perception suite due to its fundamental importance in helping to safely roll out autonomous vehicles. Despite Elon Musk’s claims to the contrary, the AV industry at large is convinced about the key relevance of this sensor and its capabilities for the success of autonomy.
Once an autonomous car hits the road, it collects huge amounts of data through all of these sensors. But what’s the destiny of that data, and what is it used for? One of the most important uses of that data is to train machine learning models so that autonomous cars, or any other autonomous system, can learn how to navigate the world.
But how does a model learn from this data? Well, the answer is ‘data annotation and labeling’ and involves an astonishing amount of manual work. In fact, it can take up to 800 man-hours to annotate just one hour of driving.
Everything in each frame needs to have a name attached to it. On a practical level, it means that every frame of collected data needs to be vetted by humans using their brain, who then label and annotate every object in the scene, or at least double check the labels automatically generated by algorithms. Just like a child in elementary school who colors drawings according to specific categories, we also teach computers to recognize and categorize objects in pretty much the same way.
In practice, this task involves drawing bounding boxes around objects or painting every pixel according to the class of object they belong to, a process known as ‘semantic segmentation.’


When lidar comes into play things get more complicated, even though the concept behind labeling remains pretty much the same. This is because lidar datasets look like clouds of points. Lidar works by emitting laser beams all around and measuring the time-of-flight of the signal bumping from an object back to the receiver. In this way, lidar can build a 3D representation of the world by drawing a point in the space every time one of its lasers hits something. Or, to be more precise, that is currently our best way of visualizing data collected by lidar.
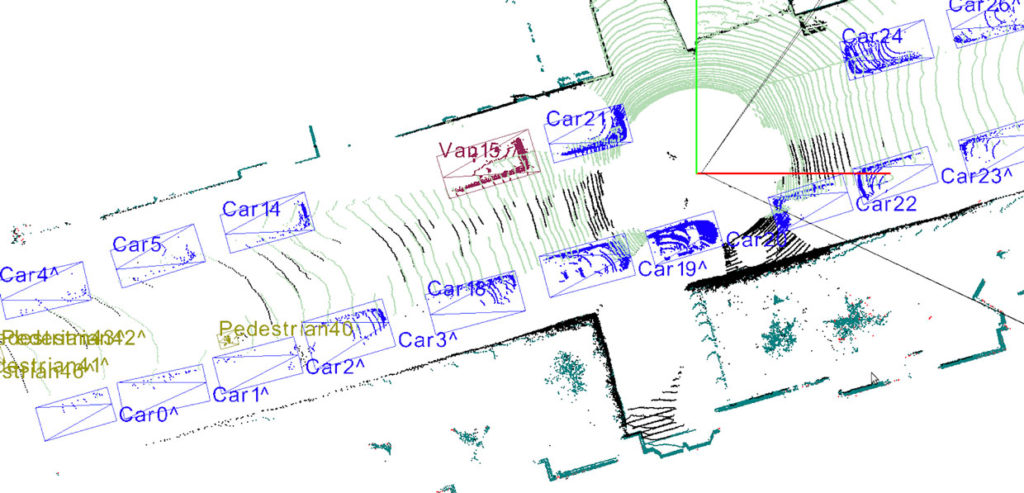
Lidar annotation is very similar to image labeling in its essence but different in practice for a simple reason: the point cloud is a 3D representation on a flat screen. In addition, humans have to deal with a huge amount of points (in the order of millions) which are not contained by well represented and defined surfaces or boundaries. So, even for the human brain, it’s not trivial to understand which point belongs to which object, and if you zoom into the point cloud image, this difficulty becomes clear. Lidar data annotation is usually performed using the same structures of classes that guide the image labeling practices, such as bounding boxes.
Are boxes the best we can do?
At this stage, one thing should be evident: We are pretty good at recognizing what is around us, and we don’t use bounding boxes or cuboids to do so. Teaching machines to recognize and interpret the environment through box labeling is very practical and relatively easy, but it is not the most detailed and insightful way of doing it.
This is why many organizations now use semantic segmentation and instance segmentation, which have far deeper levels of description and understanding than cuboids or bounding boxes. Unfortunately, lidar point cloud semantic segmentation comes with some tough challenges.
While image data is encoded in pixels, lidar data is represented by points spread throughout their 3D environment. To semantically segment lidar points means that every single point needs to be attributed to a specific class of object, and there are millions of points to be colored in a meaningful way.
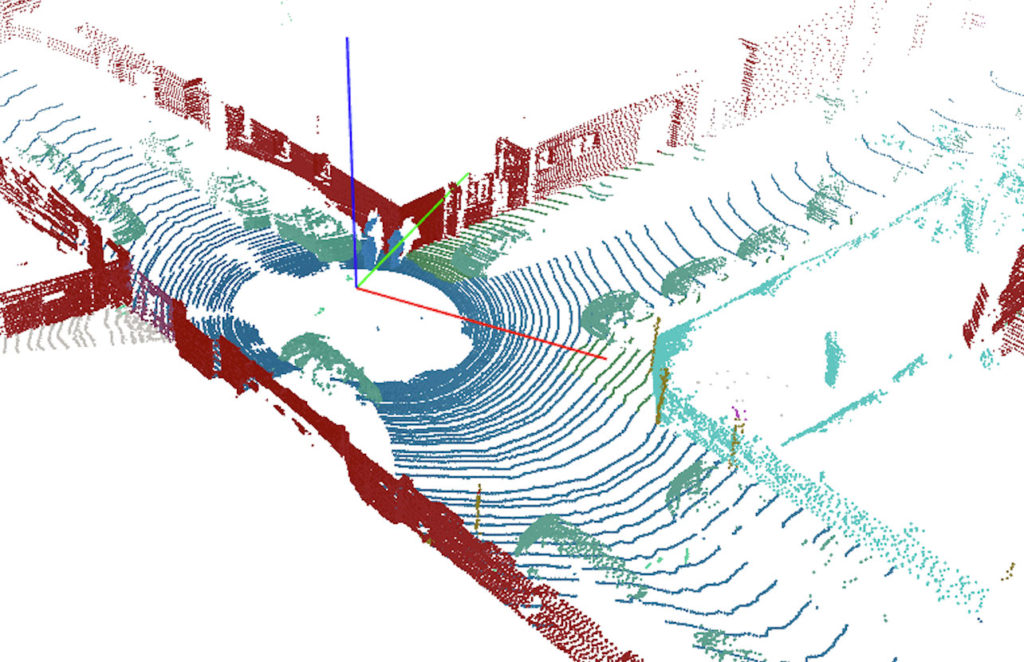
The task of manually segmenting every single point in the scene is massive and requires a lot of attention to detail. The biggest challenge in this context is represented by sequences of frames. Autonomous vehicles drive around miles of roads producing lidar sequences of data over time. So, every point in each frame needs to be labeled, turning what is already a demanding job into a massive task for humans.
Solving the sequence problem
If we focus on images and bounding boxes, the sequence problem is in fact solvable. One of the current approaches usually taken is to let humans annotate only ‘key’ frames in the sequence and have the ‘intelligent part’ of the AI software figure out where to place the labels (boxes) in the frames (images) between key frames through mathematical processes based on interpolation. But if we think about semantically segmenting lidar sequences, the problem is no longer easily solvable, meaning that segmenting long sequences of ground truth lidar data in a way that is fast, accurate and efficient is still a challenge today – not only in terms of human labor but also in terms of computational efficiency.
This is a huge problem for the whole autonomous vehicle industry. On one hand, semantically segmented lidar data can bring many advantages and unlock a wide array of innovations and advances in the field. On the other hand, it is still too cumbersome, time-consuming, resource-demanding and expensive to have lidar semantic segmentation available at large. It is arguable that the unavailability and inaccessibility of semantically segmented lidar datasets is holding back AV companies to reach important milestones in their quest for full autonomy.
Deepen.ai, a Silicon Valley based startup, has recently launched its 4D lidar annotation technology with the goal of making semantic and instance segmentation of long sequences of lidar data highly efficient and accurate. Thanks to this technology, available as an end-to-end annotation service, now it is possible to segment those long point cloud sequences in minimal time and with exceptional accuracy and efficiency, compared to what was available yesterday.
The advantages of 4D semantic segmentation
Look outside your window. Maybe you’re facing a road, a park, or another building. No matter what you’re seeing, you know that not everything in the world outside of your window can be fitted meaningfully into a box. In addition, there are many cases in which boxes overlap with each other: a person on a chair, or a car parked right under the foliage of a big tree, for example. In all of these cases, boxes cannot be very precise in specifying which is what — it’s just a loose form of annotation and labeling.
That’s why semantic segmentation is so crucial for lidar. Semantic segmented data provides autonomous vehicles with a deeper and finer interpretation of their surroundings. Moreover, how can we make sure that the autonomous systems we develop are safe enough to circulate on our roads without human intervention? Benchmarking is a crucial part of that. As of today, HD maps are being built with millimeter accuracy: every single tree, stop sign, sidewalk, needs to be located with extreme accuracy within the constructed map. As HD maps representing the real world are immensely accurate, so our algorithms should be. Training machine learning models on point level semantically segmented ground truth data is arguably the best way we have as of today to meet that level of precision.
This is just one of the many concrete applications that 4D semantic segmentation capabilities can unlock. Undoubtedly though, the ability to easily segment 3D point cloud sequences at scale will have a significant impact on many autonomous systems such as agricultural robotics, aerial drones, and even immersive 3D real-world AR and VR experiences.