
Vehicle software used to feel like a finish line: verify, sign off, ship. In modern fleets, that mindset breaks down. Deployment is where risk shows up, even after pre-release validation.
Hardware variants, uneven connectivity, partial installs and real-world edge cases turn rollout strategy into a safety variable. For advanced driver assistance system (ADAS) features, how a release is executed can matter as much as what is released. The point of staged rollout is simple: expansion decisions are based on measurable gates, not optimism.
The direction set by emerging standards
UN Regulation No. 156 requires manufacturers to operate a software update management system (SUMS). ISO 24089 adds guidance for software update engineering and governance. Neither mandates a single rollout pattern, but a staged rollout makes “controlled deployment + corrective action” legible to an auditor.

Why big-bang releases hurt
A big-bang release pushes an update to the whole fleet at once. It saves coordination work up front but maximizes blast radius when uncertainty is highest. When something regresses, the signal gets mixed with vehicle diversity, and the first week becomes a debate about whether the problem is ‘real’ or just noise. In practice, many issues are configuration dependent: uneven connectivity, partial installs, multi-ECU dependencies and hardware or compute variance can turn one defect into a dozen different symptoms. With dense sensor pipelines, small implementation changes can create performance cliffs that only appear on certain configurations, and exposure expands before a clean signal is earned.
One pattern commonly seen in practice is that a change can be ‘functionally correct’ yet quietly erode real-time margin. A perception path that used to have comfortable headroom starts running hot on a subset configuration, then intermittent dropouts or restarts appear that look random at fleet scale. With staged rollout, the canary cohort makes the issue obvious early, while it is still cheap to pause, fix and continue.
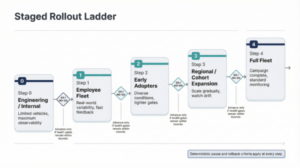
Earning the right to scale
Progressive exposure only works if programs can target and trace precisely. That starts with configuration awareness and compatibility constraints across interconnected control units, plus disciplined release identity so programs can answer: who was eligible, who actually installed and what happened afterward. This is where an eligibility manifest and a clean campaign ID stop being ‘process’ and start being survival.
Governance turns technical risk into operational rules: who can start a campaign, what evidence is required and what conditions force a pause, rollback, or escalation. If authority is not defined up front, it gets defined in the middle of an incident.
Health gates turn monitoring into permission. A gate is a defined set of signals, thresholds and observation windows that must stay within bounds before expanding to the next cohort. Gates blend update integrity signals (completion rate, retry rate, recovery success) with vehicle behavior signals (fault rates, feature availability, performance margin). One concrete example is keeping P95 cycle time within budget and restart rate at baseline during the cohort window; otherwise, the campaign pauses.

Two patterns from the field show up again and again. Performance regressions are the quiet killers, because features often fail politely by timing out rather than failing loudly. If teams do not gate on real-time health (latency, headroom, restarts), a software update problem can surface as a safety availability problem. A gate is not just a dashboard; it is a permission slip. When thresholds are pre-agreed, debate shrinks and teams execute the playbook.
Recovery is where auditors push
Staged rollouts can feel slower. It’s extra work, and nobody loves it – until the first time it prevents a fleet-wide fire drill. Not every update needs the full ladder. Teams can reserve the heaviest gating for safety-impacting changes (ADAS behavior, fault handling, real-time scheduling), while low-risk updates use a shorter canary window.
Recovery is where credibility is won or lost. Programs need predictable recovery from failed or interrupted updates, and safe behavior when an update cannot complete. For post-deployment regressions, some issues are best handled by rolling forward with a corrective update, while others warrant reverting to a known-good software set. Triggers and execution paths should be defined in advance, including how recovery works across multiple control units and migrations. A rollback runbook that’s been exercised beats a ‘we can figure it out’ promise every time.
If a program cannot explain, in plain language, how a campaign pauses and safely recovers at scale, it does not have controlled deployment.
Make evidence fall out of operations
Staged rollout can produce audit-ready evidence as a natural by-product of good operations. Before release, record an impact assessment. During rollout, capture go or no-go decisions with supporting metrics for each cohort in a campaign decision log. After rollout, publish a post-campaign report summarizing outcomes, anomalies, corrective actions and the changes that harden future gates.
As vehicles increasingly evolve through software, the safety lifecycle extends past validation and into the field. Programs that treat staged rollout, health gates and recovery design as first-class elements reduce real-world surprises while making decision-making easier to audit. In that environment, staged rollout becomes repeatable safety evidence.
Nitish Sanghi is a senior software engineer in autonomy perception at Cyngn, where he ships safety-critical perception and diagnostics for industrial autonomous vehicles. Previously, he integrated and tested autonomy software for Cruise’s Origin platform and worked on fail-safe autonomy systems at Argo AI. Earlier in his career, he built robotics and automation systems at Intuitive Surgical and Cogenra Solar. He holds an MSc in robotics from the University of Michigan.